


Am I hallucinating? 😵💫
Large Language Models (LLMs) have gained immense popularity for their ability to generate human-like text across various domains. However, despite their impressive capabilities, they are not without flaws. One of the significant challenges in using LLMs is their tendency to "hallucinate" – producing information that seems plausible but is factually incorrect, misleading, or even nonsensical.
In this article, we'll dive into what causes hallucinations in LLMs, explore critical challenges, and provide best-known strategies to address and mitigate them. So, let’s get started!

What are LLM Hallucinations?
In the context of LLMs, hallucinations refer to generated responses that are factually inaccurate or deviate from reality. These outputs may sound coherent and grammatically correct, but they contain fabricated details or data that the model "makes up."
Types of Hallucinations
Fabricated Information: When the model invents facts or references that don’t exist.
Inaccurate Interpretations: Misrepresentation of factual data or known concepts.
Logical Inconsistencies: Breakdown in logical reasoning, leading to outputs that don’t make sense contextually.
Why do LLMs Hallucinate?
Several factors contribute to hallucinations in LLMs:
Training Data: LLMs are trained on vast datasets, which include both accurate and inaccurate data. They sometimes mix these up, leading to errors.
Contextual Limitations: LLMs rely on the context provided during the conversation but may still misunderstand or lack key context.
Overconfidence in Probability: LLMs generate responses based on statistical probabilities, and when uncertain, they tend to create plausible yet incorrect answers.
Lack of Real-Time Knowledge: Even the most advanced models don’t have access to up-to-date information, relying on outdated or incomplete data.
Critical Challenges in Handling Hallucinations
1. Trust Erosion
Hallucinations erode user trust, especially when users rely on LLMs for critical decisions, such as healthcare or legal advice. This is a significant challenge for industries that depend on accuracy and reliability.
Solution: Implement human oversight mechanisms, where LLM-generated content is reviewed and verified by subject matter experts (SMEs). Tools such as feedback loops that flag errors can help monitor outputs over time.
2. Scalability in Validation
As LLMs are integrated into larger workflows, scaling the validation of each output becomes a bottleneck. In environments with high output demands, validating every response is unrealistic.
Solution: Use rule-based post-processing checks and filters to automatically detect potential hallucinations. Domain-specific language models can also be trained to mitigate inaccuracies in specialized fields.
3. Lack of Source Attribution
LLMs typically don’t cite sources or provide references, making it difficult for users to verify the authenticity of the generated content.
Solution: Enable source-tracing features within the model that link specific pieces of information to their originating data. Hybrid models that use retrieval-based systems can look up reliable sources in real-time.
4. User Over-reliance
Casual users often assume LLM-generated outputs are entirely accurate, leading to the unintentional spread of misinformation.
Solution: Educate users on the limitations of LLMs, embedding disclaimers about the accuracy of the generated data. Building an interactive system that prompts users to validate crucial information can reduce over-reliance.
5. Handling Specialized Queries
LLMs often hallucinate when asked highly specialized questions that are beyond the scope of their training data, producing confidently incorrect answers.
Solution: In scenarios requiring specialized knowledge, combine LLMs with other AI models or external knowledge bases that hold more accurate and up-to-date data for the domain in question.
Best Practices to Overcome LLM Hallucinations
Reinforcement Learning with Human Feedback (RLHF): Train models using human feedback loops to reduce the likelihood of hallucinations.
Implementing External Knowledge Sources: Enhance LLM responses by connecting them to external APIs and knowledge bases for real-time, verified information.
Interactive User Prompts: Ask follow-up questions or prompt users to validate uncertain information. This introduces a checkpoint before moving forward with potentially hallucinated data.
Confidence Score Thresholding: Program models to generate a confidence score for each response. If the score is low, either flag it for review or withhold the response until verification is completed.
Cross-Validation with Multiple LLMs: Use multiple models to answer the same question and compare their outputs. Inconsistent answers can be flagged for further investigation.
Scenarios and Solutions
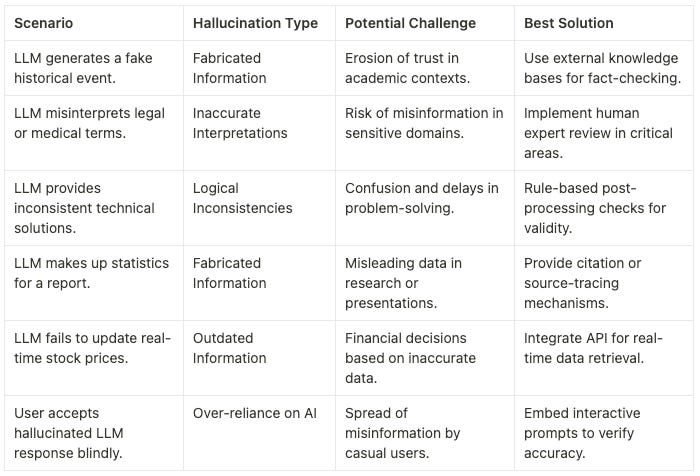
Last words
While LLMs offer immense potential across industries, managing and mitigating their hallucinations is crucial to ensuring their reliable application. By recognizing the root causes, implementing safeguards, and educating users, you can build systems that better handle inaccuracies. The key is to approach LLMs as highly capable assistants that still require a robust validation framework to avoid the pitfalls of hallucination.
I would love to know in comments the strategies that you have been using to reduce hallucinations!
Credits 🙏
Writers- Cheers to our guest writer, Kshitij Mohan
Sponsors- Thanks to our sponsors Typo AI - Ship reliable software faster
Loving our content? Consider subscribing & get weekly Bytes right into your inbox👇
If you’re pleased with our posts, please share them with fellow Engineering Leaders! Your support helps empower and grow our groCTO community.